Introduction
The vision of the Adaptive Intelligence Research (AIR) Group at Changwon National University is a ‘Making the Great! Making the New!’.
Our work ranges from basic research in computational linguistics to key applications in human language technology and covers areas such as statistical machine translation, opinion mining, and probabilistic parsing and tagging.
A distinguishing feature of the AIR Group is our effective combination of sophisticated and deep linguistic modeling and data analysis with innovative probabilistic and machine learning approaches to NLP. Our research has resulted in state-of-the-art technology for robust, broad-coverage natural-language processing in many languages. These technologies include our part-of-speech tagger for Korean, English, and Chinese; a universal named entity spotter for Korean; a high-performance probabilistic parser for Korean.
Professor

Jeong-Won Cha.
[CV]
His research interests are natural language processing, machine learning, deep learning.
Research Scientist
Ph.D. students


김중한
Interests
인공지능 정책
CV_[PDF]
Master students

오채민
Interests
Controllable Text Generation

조지원
Interests

최수찬
Interests

이범석
Interests

최수영
Interests
금동한
Interests
이진희
Interests
Undergraduate students

김도원
Interests
Intern student
Alumni

이현우
2009. 2. 석사 졸업
Naver 자연어처리팀

배민영
2010. 2. 석사 졸업
쌍용정보통신

안유미
2010. 2. 학부 졸업
롯데정보통신

성병기
2012. 2. 학부 졸업
Naver 자연어처리팀

서가은
2013. 2. 학부 졸업
카카오









Group Photo

2012.10.18

2013.2.15
2013년 전기 졸업식

2014.2.11
샌프란시스코 피어 39

2015.2.4
일본 유후인

2015. 3. 5

2015.4.18
창원 세븐스프링스

2017. 2.28
중국 청도

2017.9.1
서울 양재 BHC
Research
M3 (Multimodal to Multimodal with external Memory)
M3는 외부 메모리를 이용할 수 있고 멀티모달을 입력하여 멀티모달을 출력할 수 있는 AIR 랩의 플랫폼이다.
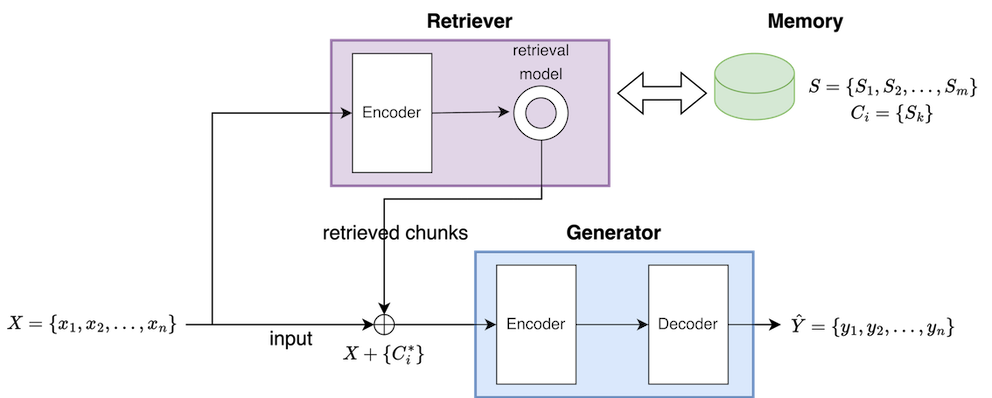
여기서 각 변수는 다음과 같이 정의된다.
\[x_i, S_j, y_k \in \{\text{multimodal}\}\]
M3를 사용하여 다음과 같은 주제를 연구한다.
- 생성기 개선 연구: 문장 생성 능력을 개선한다. 또한 원하는 형식의 문장을 생성하기 위한 연구를 진행한다.
- 검색기 개선 연구: 유사도 기반 검색, 단계별 추론 등의 연구를 진행한다.
- 입력, 출력, 외부 메모리 표현법 연구: 텍스트와 함께 이미지 등 다른 모달을 함께 사용할 수 있는 방법 연구
- 학습방법 연구: 증강 언어모델(Augmented Language Model)에 적합한 학습 방법 연구
M3를 기반으로 하는 프로젝트
-
Controllable Text Generation:
-
KB based Task Oriented Dialogue
-
Combined Resolution of Ellipses and Anaphora in Dialogues
-
Dense Retrieval for QA
-
Visual Language Model
NLTKo(NLTK with Korean language features)
NLTKo는 기존의 NLTK에 한국어 처리를 위한 함수들과 추가적인 기능들을 확장한 도구이다. 확장된 기능은 다음과 같다.
- 한국어 토크나이저
- 한국어 전처리 (자소분리, 자소결합, 문자판별 등)
- 한국어 분석기 (품사태거, 의존구문분석기, 개체명분석기, 한국어WSD)
- 번역기능 (한국어: 영어)
- 한국어 세종 시소러스 검색 (영어 Wordnet 대체)
- 각종 평가 방법 (BLEU, ROUGE, F1, MAUVE, BERT Score 등)
- 정렬 방법 (Needleman-Wunsch 알고리즘, Hirschberg 알고리즘 등)
- 거리 계산 방법 (Levenshtein Edit Distance, Wasserstein Distance 등)
- 검색 방법 (Faiss-Semantic 검색 등)
이들은 모두 기존의 NLTK와 동일한 방법으로 사용할 수 있어 편의성을 높였다.
Software
- Espresso POS Tagger [demo(Korean), demo(English), demo(Chinese)]
- Espresso POS Tagger with automatic word segmentation (beta) [demo]
- Espresso 2: United Korean Language Understanding Engine [demo]
- NLTKo [Install]
- News Summarization [demo]
- Korean linguistic acceptability [demo]
- Penguin Run: For Memorizing English Vocabulary [demo]
- Sally [demo]: AI Teaching Assistant
Publication
Manuscripts
2024
- Minju Gwak, Jeong-Won Cha, Hosun Yoon, Donghyun Kang, Donghyeok An . Lightweight Transformer Model for Mobile Application Classification. Sensors. 2024; 24(2):564. https://doi.org/10.3390/s24020564 [link]
2023
- Seong S, Cha J. Domain Word Extension Using Curriculum Learning. Sensors. 2023; 23(6):3064. https://doi.org/10.3390/s23063064 [link]
2022
- Hazel Kim, Daecheol Woo, Seong Joon Oh, Jeong-Won Cha, Yo-Sub Han, ALP: Data Augmentation Using Lexicalized PCFGs for Few-Shot Text Classification, Proceedings of the AAAI Conference on Artificial Intelligence 36(10):10894-10902, June 2022 [pdf]
- 성수진, 차정원, 분류체계 자동 생성 지원을 위한 용어 벡터 생성 방법 탐색, 한글 및 한국어정보처리 학술대회(HCLT)
- 오진영, 차정원, 문맥 정보 조절을 통한 관계 추출 성능 개선, 한글 및 한국어정보처리 학술대회(HCLT)
- 박다솔, 차정원, (KSC2020 우수발표논문) 복사 매커니즘을 이용한 한국어-제주어 기계번역, 정보과학회 컴퓨팅의 실제 논문지, 정보과학회 컴퓨팅의 실제 논문지 제 28권 제 3호 [pdf]
- 성수진, 차정원,(KCC2022 우수논문) 지식베이스 기반 근거 문장을 제공하는 질의응답 모델, 한국 컴퓨터 종합학술대회(KCC)[pdf]
- 홍성태, 차정원, 키워드를 이용한 패러프레이즈 문장 생성, 한국 컴퓨터 종합학술대회(KCC)[pdf]
- 문성후, 차정원, 미분가능한 BLEU loss를 이용한 NAR 패러프레이징 생성 모델, 한국 컴퓨터 종합학술대회(KCC)[pdf]
- 노다설, 차정원, (KCC2022 학부생부문 장려상)CoLA 데이터에 적합한 딥러닝 사전 학습 모델 탐색, 한국 컴퓨터 종합학술대회(KCC)[pdf]
2021
- 성수진, 차정원, (KCC2020 우수발표논문) 단어 손실함수와 반복패널티를 추가한 트랜스포머 인코더-디코더 제목 생성 모델, 정보과학회 컴퓨팅의 실제 논문지 제 27권 제 4호 [pdf]
- 오진영, 차정원, (HCLT 2020 우수논문) 뉴럴-심볼릭 구조 기반의 관계 추출, 정보과학회 컴퓨팅의 실제 논문지 제27권 제 5호 [pdf]
- 박다솔, 장두성, 차정원, 문장 유사도를 이용한 다양한 표현의 패러프레이즈 생성, 한글 및 한국어정보처리 학술대회(HCLT)[pdf]
- 성수진, 박원주, 이용태, 차정원, 불균형 범주 분류를 위한 동적 샘플링 스케쥴러, 한글 및 한국어정보처리 학술대회(HCLT)[pdf]
- 성수진, 김성찬, 이승우, 차정원, 문맥 정보를 이용한 논문 문장 수사학적 분류, 한글 및 한국어정보처리 학술대회(HCLT)[pdf]
- 홍성태, 차정원, NLTKo 1.0: 한국어 언어처리 도구, 한글 및 한국어정보처리 학술대회(HCLT)[pdf]
- Su-Jin Seong, Ji-Uk Yoon, Jeong-Won Cha, Explainable Deep Neural Networks for Anesthesia Treatment, Anesthesia & Analgesia., (will be appeared)
2020
- 신창욱, 오진영, 차정원, 범주 불균형 분류 문제를 위한 동적 비용 민감 학습 방법, 정보과학회 컴퓨팅의 실제 논문지 제 26권 제 4호 [pdf]
- Chang-Uk Shin, Jeong-Won Cha, Multi-domain Task Oriented Dialogue System Using Word Constraints, AAAI(Association for the Advancement of Artificial Intelligence) [pdf]
- 신창욱, 장두성, 차정원, 멀티태스크 학습을 이용한 대화 상태 추적 시스템, 한국 컴퓨터 종합학술대회(KCC) [pdf]
- 성수진, 이승우, 차정원, 단어 손실함수를 추가한 트랜스포머 인코더-디코더 기반의 제목 생성 모델, 한국 컴퓨터 종합학술대회(KCC) [pdf]
- 오진영, 차정원, 뉴럴-심볼릭 구조 기반의 관계 추출, 한글 및 한국어정보처리 학술대회(HCLT) [pdf]
- 박다솔, 차정원, 트랜스포머와 판별기를 이용한 비병렬 데이터의 텍스트 스타일 변환, 한글 및 한국어정보처리 학술대회(HCLT) [pdf]
- 박다솔, 김영길, 차정원, 포인터 생성 네트워크를 이용한 패러프레이즈 생성, 한글 및 한국어정보처리 학술대회(HCLT) [pdf]
- 신창욱, 장두성, 차정원, 규칙 및 통계 기반 시스템의 결과를 활용하는 대화 상태 추적 시스템의 개발 및 사용자 시뮬레이터를 이용한 평가, 한글 및 한국어정보처리 학술대회(HCLT) [pdf]
- 성수진, 권수범, 윤지욱, 오진영, 차정원, 마취용 처치 추천을 위한 설명 가능한 딥뉴럴 네트워크, 정보과학회 컴퓨팅의 실제 논문지 제 26권 제 12호 [pdf]
- 박다솔, 차정원, 복사 매커니즘을 이용한 한국어-제주어 기계번역, 한국 소프트웨어 종합 학술대회(KSC) [pdf]
- 성수진, 차정원, 리워드를 이용한 설명 가능 마취용 처치 추천 딥뉴럴 네트워크, 한국 소프트웨어 종합 학술대회(KSC) [pdf]
2019
- 성수진, 권수범, 윤지욱, 오진영, 차정원, 마취용 처지 추전을 위한 설명 가능한 딥뉴럴 네트워크, 한국 소프트웨어 종합 학술대회(KSC) [pdf]
- 김민석, 신창욱, 오진영, 차정원, XLNet을 이용한 한국어 구문분석, 한글 및 한국어정보처리 학술대회(HCLT) [pdf]
- 박다솔, 손정우, 김선중, 차정원, 심층 네트워크의 과계산에 대한 고찰, 한글 및 한국어정보처리 학술대회(HCLT) [pdf]
- 김정무, 이승우, 차정원, 다중 정보와 Self-Attention을 이용한 관계 추출, 한글 및 한국어정보처리 학술대회(HCLT)[pdf]
- 성수진, 차정원, 깊이에 따른 중간 단계 분류기 내부 학습 경향 분석 및 고찰, 한글 및 한국어정보처리 학술대회(HCLT) [pdf]
- 오진영, 차정원, GAN에서 그래프 탐색을 이용한 유창한 문장 생성, 한글 및 한국어정보처리 학술대회(HCLT) [pdf]
- 박다솔, 손정우, 김선중, 차정원, Multi-head Self-Attention을 이용한 비디오 캡션 생성, 한국 컴퓨터 종합학술대회(KCC) [pdf]
- 신창욱, 차정원, 범주 불균형 분류 문제를 위한 동적 비용 민감 학습, 한국 컴퓨터 종합학술대회(KCC) [pdf]
- 오진영, 차정원, 유전 알고리즘을 이용한 텍스트 GAN, 한국 컴퓨터 종합학술대회(KCC) [pdf]
- 신창욱, 권오욱, 차정원, 동적 가중치 부여 다중 비용 함수를 이용한 범주 불균형 데이터 분류, 한국 컴퓨터 종합학술대회(KCC) [pdf]
- 성수진, 방준성, 차정원, 합성곱 신경망 구조를 이용한 문서 범주 관련 키워드 추출, 한국 컴퓨터 종합학술대회(KCC) [pdf]
- 오진영, 김정무, 차정원, Weighted BLEU: 단어 가중치 기반 BLEU, 한국 컴퓨터 종합학술대회(KCC) [pdf]
- 박다솔, 차정원, 객체 Attention을 이용한 이미지 캡션 생성, 한국 정보과학회 논문지[pdf]
- Chang-Uk Shin, Jeong-Won Cha, Top-K Attention Mechanism for Complex Dialogue System, DSTC7 [pdf]
2018
- 박다솔, 차정원, 퍼지 범주 표현과 준지도 심층 신경망을 이용한 트위터 혐오 발언 문장 탐지, 한국 정보과학회 논문지 [pdf]
- 성수진, 신창욱, 박성재, 차정원, CNN Sequence-to-Sequence를 이용한 대화 시스템 생성, 한글 및 한국어 정보처리 학술대회(HCLT2018) [pdf]
- 신창욱, 차정원, 대화에서 멀티태스크 학습을 이용한 감정 및 화행 분류, 한글 및 한국어 정보처리 학술대회(HCLT2018) [pdf]
- 김정무, 신창욱, 차정원, Q-Net:질문 유형을 추가한 기계 독해, 한글 및 한국어 정보처리 학술대회(HCLT2018) [pdf]
- 성수진, 박성재, 정인규, 차정원, Multi-Task Learning에서 공유 공간과 성능과의 관계 탐구, 한글 및 한국어 정보처리 학술대회(HCLT2018) [pdf]
- 하은주, 오진영, 차정원, 국어 감정분석을 위한 말뭉치 구축 가이드라인 및 말뭉치 구축 도구, 한글 및 한국어 정보처리 학술대회(HCLT2018) [pdf]
- 오진영, 차정원, Ontofitting: 의미 표현을 위한 벡터 조정, 한글 및 한국어 정보처리 학술대회(HCLT2018) [pdf]
- Su-Jin Seong, Seong-Jae Park, Tae-Ho Park, Chang-Uk Shin, Da-Sol Park, Jeong-MooKim, Jeong-Won Cha, Epidemic Respiratory Disease Prediction Using Ensemble Method, International Conference on Future Information & Communication Engineering(ICFICE)
- 박태호, 차정원, 세종 형태의미분석 말뭉치와 세종의미사전의 용언 의미번호 불일치 문제 해결, 한국정보과학회 논문지
- Chang-Uk Shin, Jeong-Won Cha, End-to-End Task Dependent Recurrent Entity Network for Goal-Oriented Dialog Learning, Computer Speech & Language [doi]
2017
- Jung-Yeul Park, Jeong-Won Cha, Mija Kim, Open Language Resources for Korean – Best practices and discussion for Korean language processing, Language Resources and Evaluation(LRE) [pdf]
- 박다솔, 신창욱, 신영태, 차정원, 준지도 학습 심층 신경망을 이용한 트위터 혐오 발언 문장 탐지, 한국 소프트웨어 종합 학술대회(KSC) [pdf]
- 성수진, 박성재, 차정원, 일별 굴 생산량의 예측 가능성에 관한 연구, 한국 소프트웨어 종합 학술대회(KSC) [pdf]
- 신창욱, 차정원, Dynamic Memory Network를 이용한 End-to-End 레스토랑 예약 대화 시스템, 한국 소프트웨어 종합 학술대회(KSC) [pdf]
- Chang-Uk Shin, Jeong-Won Cha, Learning Dynamic Memory Networks with Two Views, Dialog System Technology Challenges(DSTC) [pdf]
- Jung-Yeul Park, Loic Dugast, Jeen-Pyo Hong, Chang-Uk Shin and Jeong-Won Cha, Building a Better Bitext for Structurally Different Languages through Self-training, IJCNLP 2017 Workshop on Curation and Application of Parallel and Comparable Corpora(Cupral) [pdf]
- 박성재, 차정원, LSTM을 이용한 한국어 이미지 캡션 생성, 한글 및 한국어 정보처리 학술대회(HCLT2017) [pdf]
- 신창욱, 차정원, MTRNN을 이용한 한국어 대화 모델 생성, 한글 및 한국어 정보처리 학술대회(HCLT2017) [pdf]
- 박다솔, 차정원, 워드 임베딩과 유의어를 활용한 단어 의미 범주 할당, 한국정보과학회 논문지 [pdf]
- 박태호, 차정원, 형태 의미 정보를 이용한 한국어 의미역 결정, 한국 컴퓨터 종합학술대회(KCC) [pdf]
- 신창욱, 차정원, skip-thought 벡터를 이용한 한국어 의미 표현, 한국 컴퓨터 종합학술대회(KCC) [pdf]
- 박성재, 차정원, CNN을 이용한 대화와 같은 짧은 문장에서 개체명 인식, 한국 컴퓨터 종합학술대회(KCC) [pdf]
- Da-Sol Park and Jeong-Won Cha, Extension of Semantic Lexicon Using Word Embeddings and Synonyms, INFORMATION-An International Interdisciplinary Journal [pdf]
- Tae-Ho Park and Jeong-Won Cha, Feature verification for Korean Semantic Role Labeling, INFORMATION-An International Interdisciplinary Journal [pdf]
2016
- 박태호, 신창욱, 박성재, 박다솔, 신영태, 차정원, 한국어 의미 분석을 위한 세종의미망 확장, 정보과학회 동계학술대회 [pdf]
- Jung-Yeul Park, Jeen-Pyo Hong and Jeong-Won Cha, Korean Language Resources for Everyone, Pacific Asia Conference on Language, Information and Computation(PACLIC) [pdf]
- 박다솔, 차정원, 워드 임베딩을 이용한 세종 전자사전 확장, 제28회 한글 및 한국어 정보처리 학술대회(HCLT2016) [pdf]
- 박태호, 차정원, CRF를 이용한 복수 의미역 문제 해결, 제28회 한글 및 한국어 정보처리 학술대회(HCLT2016) [pdf]
- 박태호, 차정원, Korean Semantic Role Labeling Using CRFs, IICCC2016 [pdf]
- 박태호, 차정원, CRFs 기반의 한국어 의미역 부착 성능 향상을 위한 자질 선택, 한국정보과학회지[pdf]
- 박태호, 신창욱, 박성재, 박다솔, 차정원, Rough Set을 이용한 형태소 품사 태깅 코퍼스 오류 정량화, 한국 컴퓨터 종합학술대회 논문집(KCC16) [pdf]
- 신창욱, 차정원, Improving Korean dependency parsing performance using predicate-argument features, APIC-IST2016 [pdf]
- 최윤수, 차정원, Word Embedding 자질을 이용한 한국어 개체명 인식 및 분류, 한국정보과학회 논문지 [pdf]
- 박태호, 차정원, 커널 Ripple-Down Rule을 이용한 태깅 말뭉치 오류 자동 수정, 한국정보과학회 논문지 [pdf]
2015
- 신창욱, 차정원, CRFs를 이용한 구문분석기의 오류 분석 및 자질 추천, 정보과학회 동계학술대회 [pdf]
- 최윤수, 차정원, Word Embeddings 자질을 이용한 한국어 개체명 인식 및 분류, 정보과학회 동계학술대회 [pdf]
- 박태호, 차정원, CRFs 기반의 한국어 의미역 결정, 한글 및 한국어 정보처리 학술대회(HCLT2015) [pdf]
- 신창욱, 박성재, 차정원, Khann 2 : 경험기반 고효율 한국어 품사태깅 도구, 한국 컴퓨터 종합학술대회 논문집(KCC15) [pdf]
- 김중한, 최윤수, 박태호, 개체명 부착 말뭉치에서 자동 오류 수정, 한국 컴퓨터 종합학술대회 논문집(KCC15) [pdf]
Patents
- 차정원, 성수진, 의료 처치방안 추천 시스템, (출원번호 제 10-2020-0042763호)
- 차정원, 박다솔, 신창욱, 퍼지 범주 표현을 이용한 확률 레이블 부착 알고리즘을 사용한 분류 방법, (등록번호 제 10-2098461호)
- 차정원, 박다솔, 비디오 캡션 생성장치 및 방법, (국제출원, 출원번호 PCT/KR2019/017428)
- Jeong-Won Cha, Tae-Ho Park, Chang-Uk Shin, Da-Sol Park, Seong-Jae Park, DEVICE FOR AUTOMATICALLY DETRCTING MORPHEME PART OF SPEECH TAGGING CORPUS ERROR BY USING ROUGH SET, AND METHOD THEREFOR, (미국, 출원번호 16/345, 959)
- 차정원, 김정무, 포인트 네트워크를 이용한 트리플 추출방법 및 그 추출 장치, (출원번호 제 10-2019-0144846호)
- 차정원, 성수진, 멀티 태스크 러닝 분류기 학습장치 및 방법, (출원번호 제 10-2019-0144866호)
- 차정원, 박다솔, 적대적 학습 방법을 이용한 문장 생성 시스템 및 방법, (등록번호 제 10-2030289호)
- 차정원, 박태호, 신창욱, 박다솔, 박성재, 커널 RDR을 이용한 태깅 말뭉치 오류 자동수정방법, (등록번호 제 10-1813683호)
- 차정원, 박태호, 신창욱, 박다솔, 박성재, 러프 셋을 이용한 형태소 품사 태깅 코퍼스 오류 자동 검출 장치 및 그 방법, (등록번호 제 10-20836996호)
- 차정원, 서가은, 모바일 기기에서 사물이 카메라 화면의 적절한 위치에 있는지 판단하는 방법, (등록번호 제 10-1384784 호)
- 정희석, 박영희, 차정원, 사용자 정보에 따른 스토리 생성 장치 및 방법, P2011-0029154 (출원일자: 2011-03-31), P2011-0055102, 2011.06.08
- Hee-Seok Jeong, Young-Hee Park, Jeong-Won Cha, APPARATUS AND METHOD FOR GENERATING STORY ACCORDING TO USER INFORMATION, SP11185-US
- 김래현, 한요섭, 조현철, 차정원, ASSESSMENT OF A USER REPUTATION AND A CONTENT RELIABILITY
- 김래현, 한요섭, 차정원, 키워드 정련 장치 및 방법과 그를 위한 컨텐츠 검색 시스템 및 그 방법, (등록번호 제 10-1105798 호)
- 김래현, 한요섭, 차정원, 조현철, 리사, 소셜 네트워크를 통한 사용자 신뢰도 평가 방법 및 이를 통한 컨텐츠 신뢰도 평가 시스템 및 방법 (등록번호 제 10-2010-0025930 호), 2010. 03.23
- 차정원, 이종구, 문서 표절 탐색 방법 및 장치{Method and apparatus for detecting document plagiarism}, (등록번호 제 10-0999488-00-00 호)
- 이근배, 이원일, 차정원. 음절 정규화 표현사전을 이용한 미등록어 분석방법 및 미등록어를 포함한 문장의 형태소 분석 방법, (등록번호 제 0320348), 2001.12.27
Technology transfer
- TheIMC, Espresso:한국어품사태거, 2014
- TheIMC, Espresso:한국개체명인식기, 2016
- 한국전자부품연구원, Espresso:한국어품사태거, 2015
- 한국전자부품연구원, Espresso:한국어개체명인식기, 2016
- KT, Espresso:한국어형태소태거, 2015
- KT, Espresso:한국어구문분석기, 2016
- SKT, Espresso:한국어구문분석기, SRL, Co-reference resolution, 2016